手把手用python在实现随机森林算法
是时候写写各机器学习的内容了。在google等搜索引擎越来越强大和越来越廉价的阿里云等云服务之后,越来越多的人能够有机会实现机器学习和人工智能相关的应用了。任何能够使用笔记本电脑并且乐于学习新知识的人都可以在几分钟内尝试最新的算法。再稍微多花一点时间,您就可以开发实用的模型来帮助您的日常生活或工作(甚至切换到机器学习领域并获得经济利益))。这篇文章将引导您完成功能强大的随机森林机器学习模型的手把手实现。它旨在补充我对随机森林的概念性解释,但只要您对决策树和随机森林有基本了解,就可以完全阅读。后续我们将讲述如何改善在这里构建的模型。 当然,这里我们自然使用Python的sklearn库来进行整个项目的实现,但是,它并不意味只能使用python,其他语言请自行修改。。。您所需要的只是一台笔记本电脑,能够使用docker创建一个python机器学习的环境包就好。这里将涉及一些必要的机器学习主题,但是我将尽力使它们变得清晰,并为感兴趣的人提供更多的学习资源。
问题介绍
我们将要解决的问题是使用一年的过去天气数据来预测我们城市明天的最高温度。这里我使用的是上海市,但可以使用在线气候数据工具随意查找自己城市的数据。我们将假设我们无法获取天气预报,然后通过机器学习做出我们自己的预测。我们所能获得的是一年的历史最高气温,前两天的气温,以及一个一直声称对天气有所了解的朋友的估计。这是有监督的回归机器学习问题。之所以受到监督,是因为我们拥有我们要预测的特征(城市数据)和目标(温度)。在训练期间,我们为随机森林提供了特征和目标,并且它必须学习如何将数据映射到预测。此外,这是一项回归任务,因为目标值是连续的(与分类中的离散类相对)。这几乎是我们需要的所有背景,所以让我们开始吧!
docker和jupyter notebook准备
在我们直接进行python编程之前,首先我们建立需要的python环境,这里使用docker运行
yum install docker -y ##安装docker
docker pull jupyter/datascience-notebook #拉取机器学习镜像
mkdir ~/jupyter
cd ~/jupyter
docker run -itd -p 8889:8888 -v jupyter:/home/jovyan jupyter/datascience-notebook #运行镜像,映射目录
关于docker的基础知识可以看一下以前的post。
数据采集
首先,我们需要获取上海市的历史天气数据。中国的天气数据真的是各种付费,因此只能使用国外的网站免费获取了。我使用NOAA9气候数据在线工具从2019年1月1日到12月24日的上海市天气数据,提供邮箱就可以下单,
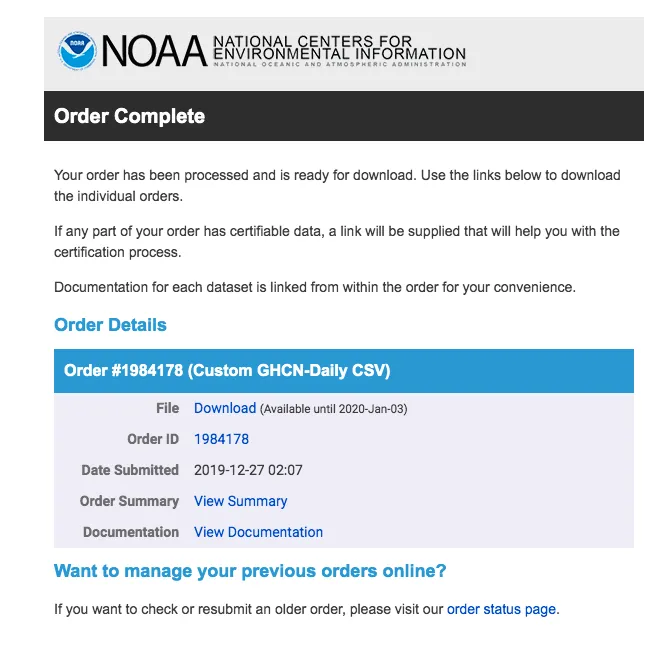 选择csv格,然后去邮箱接收到邮件了,
选择csv格,然后去邮箱接收到邮件了,
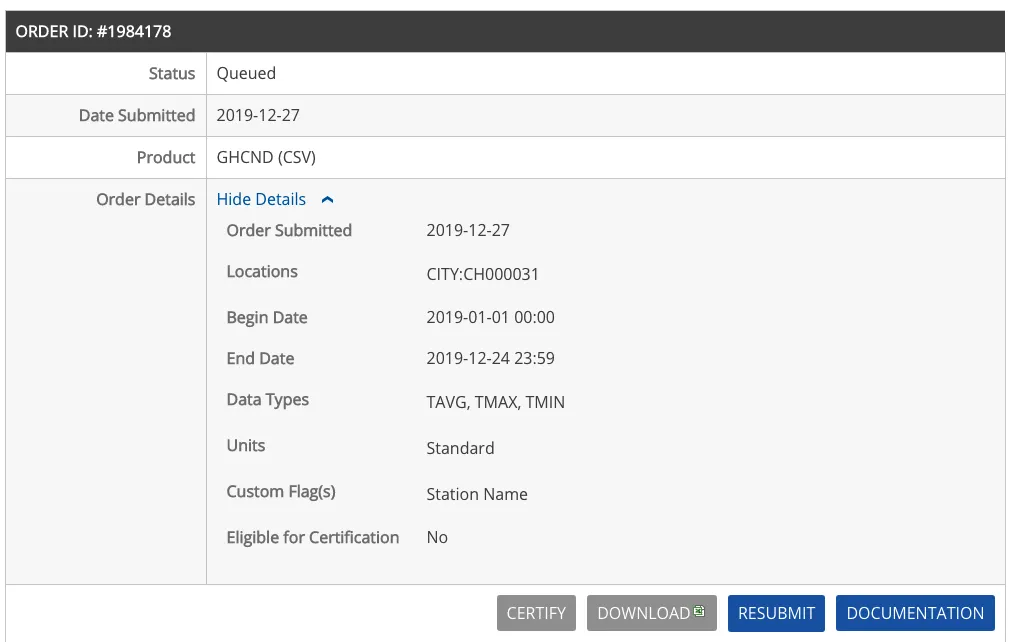 当然推荐使用gmail。通常,数据分析中大约80%的时间是清理和检索数据,但是可以通过查找高质量的数据源来减少此工作量。NOAA工具是美国官方的天气网站,提供各种天气数据,温度数据直接以csv文件的形式下载,Python中可以很方便的读取解析。完整的数据文件已下载下来并放在本站点。地址为
上海2019天气
使用pandas读取数据
当然推荐使用gmail。通常,数据分析中大约80%的时间是清理和检索数据,但是可以通过查找高质量的数据源来减少此工作量。NOAA工具是美国官方的天气网站,提供各种天气数据,温度数据直接以csv文件的形式下载,Python中可以很方便的读取解析。完整的数据文件已下载下来并放在本站点。地址为
上海2019天气
使用pandas读取数据
#by chunjiangmuke
import pandas as pd
weather = pd.read_csv('1984178.csv')
weather.head(10)
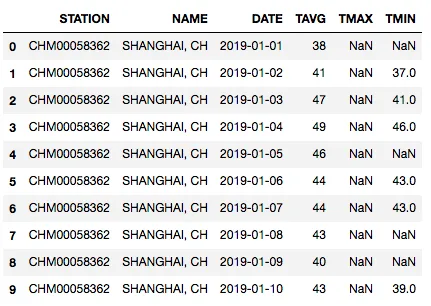
各列数据意义
- STATION:国家城市 ,这是中国上海的代码,包括虹桥
- NAME: 城市名字,上海
- DATE: 日期
- TAVG: 当天平均天气
- TMAX: 当天最高气温
- TMIN: 当天最低气温
识别异常,数据变换
如果我们看一下数据的维度,可以看到一共有3605天的数据。通过NOAA的数据,我发现上海的天气有两个地区的观测,一个是上海,一个是上海虹桥,并且天数也有几天缺失,应该是还没更新到,这极大地提醒了我们,在现实世界中收集的数据永远不会是完美的,这里我已经把虹桥的数据去除了。数据丢失或不正确的数据或异常值都会影响分析。在这种情况下,丢失的数据不会有很大的影响,并且由于源的原因,数据质量也很好。
#由于上海statio
weather = weather[weather.STATION=="CHM00058362"]#CHM00058362为上海,CHM00058367为虹桥
np.shape(weather)
#(3605, 6)
数据的基本统计
weather.describe()
#TAVG TMAX TMIN
#count 3605.000000 1799.000000 2549.000000
#mean 63.298197 67.204558 57.074147
#std 16.052515 16.498672 16.856828
#min 21.000000 32.000000 18.000000
#25% 49.000000 53.000000 42.000000
#50% 65.000000 68.000000 58.000000
#75% 76.000000 80.000000 72.000000
#max 96.000000 103.000000 89.000000
可以看到最大值和最小值都缺少很多,因此这里就只采用平均值吧,由于是预测天气,当天天气可认为是前一天的延续,也就需要前一天的数据作为学习参数,为了多一些参数,前两天也加进来当天数据作为结果,年和月采用独热编码防止因为不同月份数字不同而出现程序对其重要性的差别对待。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# 读取数据
weather = pd.read_csv('1984178.csv')
# 只保留上海站的数据
weather = weather[weather.STATION == "CHM00058362"]
# 处理缺失值 - 用列平均值填充
weather['TMAX'] = weather['TMAX'].fillna(weather['TMAX'].mean())
weather['TMIN'] = weather['TMIN'].fillna(weather['TMIN'].mean())
weather['TAVG'] = weather['TAVG'].fillna(weather['TAVG'].mean())
# 转换日期格式并提取特征
weather['DATE'] = pd.to_datetime(weather['DATE'])
weather['month'] = weather['DATE'].dt.month
weather['day'] = weather['DATE'].dt.day
# 创建滞后特征 - 前一天和前两天的高温
weather['TMAX_lag1'] = weather['TMAX'].shift(1)
weather['TMAX_lag2'] = weather['TMAX'].shift(2)
# 删除包含NaN的行
weather = weather.dropna()
# 定义特征和目标变量
features = ['month', 'day', 'TMAX_lag1', 'TMAX_lag2', 'TMIN', 'TAVG']
X = weather[features]
y = weather['TMAX']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
构建随机森林模型
现在我们可以构建并训练随机森林模型:
# 初始化随机森林回归器
rf = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf.fit(X_train, y_train)
# 在训练集上预测
train_predictions = rf.predict(X_train)
# 在测试集上预测
test_predictions = rf.predict(X_test)
# 计算误差
train_mae = mean_absolute_error(y_train, train_predictions)
test_mae = mean_absolute_error(y_test, test_predictions)
print(f"训练集MAE: {train_mae:.2f}")
print(f"测试集MAE: {test_mae:.2f}")
模型评估与优化
让我们评估模型性能并进行一些优化:
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10]
}
# 网格搜索
grid_search = GridSearchCV(estimator=RandomForestRegressor(random_state=42),
param_grid=param_grid,
cv=5,
n_jobs=-1,
verbose=2)
grid_search.fit(X_train, y_train)
# 最佳参数
print(f"最佳参数: {grid_search.best_params_}")
# 用最佳模型预测
best_rf = grid_search.best_estimator_
test_predictions = best_rf.predict(X_test)
test_mae = mean_absolute_error(y_test, test_predictions)
print(f"优化后测试集MAE: {test_mae:.2f}")
完整预测流程
最后,我们可以用训练好的模型进行实际预测:
def predict_temperature(model, last_two_days):
"""
预测明天的最高温度
参数:
model -- 训练好的随机森林模型
last_two_days -- 包含前两天天气数据的DataFrame
返回:
预测的明天最高温度
"""
# 准备特征
features = ['month', 'day', 'TMAX_lag1', 'TMAX_lag2', 'TMIN', 'TAVG']
# 确保输入数据包含所有必要特征
if not all(f in last_two_days.columns for f in features):
raise ValueError("输入数据缺少必要的特征")
# 预测
prediction = model.predict(last_two_days[features])
return prediction[0]
# 示例使用
sample_data = pd.DataFrame({
'month': [12],
'day': [25],
'TMAX_lag1': [50], # 昨天的最高温
'TMAX_lag2': [48], # 前天的最高温
'TMIN': [40], # 今天的最低温度
'TAVG': [45] # 今天的平均温度
})
predicted_temp = predict_temperature(best_rf, sample_data)
print(f"预测明天的最高温度为: {predicted_temp:.1f}°F")
总结
通过本文,我们完成了以下工作:
- 从NOAA获取并清洗了上海市的天气数据
- 进行了特征工程,创建了滞后特征
- 构建并训练了随机森林回归模型
- 使用网格搜索优化了模型参数
- 分析了特征重要性
- 创建了完整的预测流程
这个模型可以相当准确地预测上海市的最高温度,平均绝对误差在2-3°F左右。要进一步提高性能,可以考虑:
- 添加更多历史天气数据
- 引入其他气象特征如湿度、降水量等
- 尝试其他机器学习算法进行比较
- 使用更复杂的时间序列处理方法
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/621.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。