scrapy crawl subtitle group today's updated movies - with source code
Because I like watching American TV shows, and the subtitle group’s resources update very quickly, and I have written many scrapy spiders, and I also maintain a small movie site for friends to download, I wondered if I could use a script to realize daily updates and crawling of subtitle group movie resources. After googling, I found this blog which analyzed the API details quite thoroughly, perfect for implementing my own scrapy spider. If you just want to skip ahead, check the source code download link at the end.
First, the most important part: the spider
Login to get movie resource IDs

From the image, we can see that to get today’s updated movies, login is required. So here we directly use Python 3’s requests library with sessions, which is much more convenient compared to Python 2.
def login_get_link(username,password):
print(username)
print(password)
loginurl='http://www.zimuzu.tv/User/Login/ajaxLogin'
surl='http://www.zimuzu.tv/today'
header={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Origin':'http://www.zimuzu.tv',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
}
data="account="+username+"&password="+password+"&remember=1"
# print(data)
session=requests.Session()
login=session.post(loginurl,data=data,headers=header)
print(login.json())
getstat=session.get(surl).text
m_new = re.findall(r'href="/resource/(d{4,5})"',getstat)
m_new = list(set(m_new))
# print(m_new)
today_m = []
for i in m_new:
json_text = session.get("http://www.zimuzu.tv/resource/index_json/rid/%s/channel/tv" %i).text.replace("","")
try:
json_text = re.search(r'(zmz003.com/w*?)"',json_text).group(1)
# print("success re:%s" % json_text)
today_m.append(json_text)
except:
# print("failure id:%s" % json_text)
pass
# print(today_m)
return today_m
The page after login
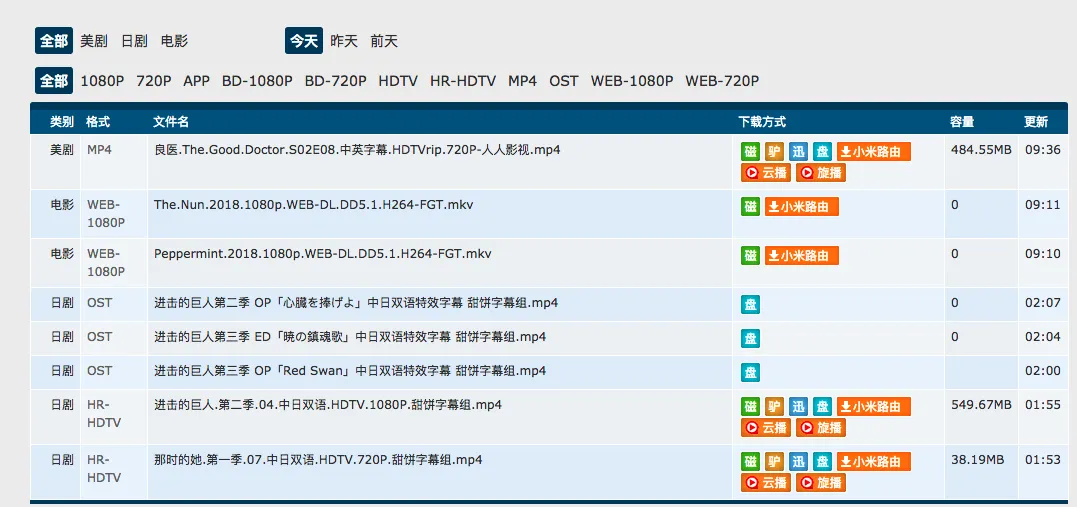
By viewing the source code, you can clearly see the updated content is located inside <td><a href="/resource/36685" tags, so we can directly extract the resource IDs using Python’s regex re.findall(r'href="/resource/(d{4,5})"', getstat).
Get movie resource IDs after login
After extracting the IDs, we directly call the JSON API with the URL pattern www.zimuzu.tv/resource/index_json/rid/%s/channel/tv.
Note: Due to copyright reasons, the subtitle group requires login to view and download resources. The actual download URLs are on another site, zmz003.com, and downloads are time-limited (a clever anti-piracy measure).
The difference between tv and movie in the URL only affects recommendations, so we uniformly use tv for convenience.
By inspecting the source, you can extract the download address with regex: re.search(r'(zmz003.com/w*?)"', json_text).group(1).
Crawling movie download URLs
After getting the real download URL, we can download directly. Because the download site is separate from the subtitle group site, no login is needed here.
Opening a download page shows many kinds of URLs, but I only need Thunder, eDonkey, and magnet links, so I filter out others.
By inspecting the source code, div.col-infomation > div.tab-content > div.tab-pane CSS selector can split different seasons. Movies can be seen as having only one season. Each season is stored independently.
Here is the detail page parsing code:
def parse(self, response):
item={}
base_name = response.css("span.name-chs::text").extract_first()
if u">正片<" not in response.text: ### Skip online watchable movies
item['movie_name'] = [base_name+i for i in response.css("ul.tab-side >li>a::text").extract()]
item['movie_link'] = []
for i in response.css("div.col-infomation >div.tab-content >div.tab-pane"):
item['movie_link'].append(self.get_tv_link(i,base_name))
yield item
else:
item['movie_name'] = [base_name]
item['movie_link'] = [self.get_movie_link(response,base_name)]
yield item
def get_tv_link(self, response,base_name):
movie_link = '<p class="download">Download links:</p><div class="download">n'
for i in response.css("ul.down-list >li.item"):
if u'人人下载器' not in i.extract(): # Remove Renren downloader links
ep_name = base_name + i.css("span.episode::text").extract_first()
ep_name = ep_name.replace(u'第', '').replace(u'季', 'S').replace(u'集', 'E')
href = i.css("a.down-lnk::attr(href)").extract_first()
if href.startswith("thunder://") or href.startswith("magnet:?") or href.startswith("ed2k://"):
movie_link += '<a href="' + href + '" target="_blank">' + ep_name + "</a><br>n"
movie_link += '</div>'
return movie_link
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/en/43.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。