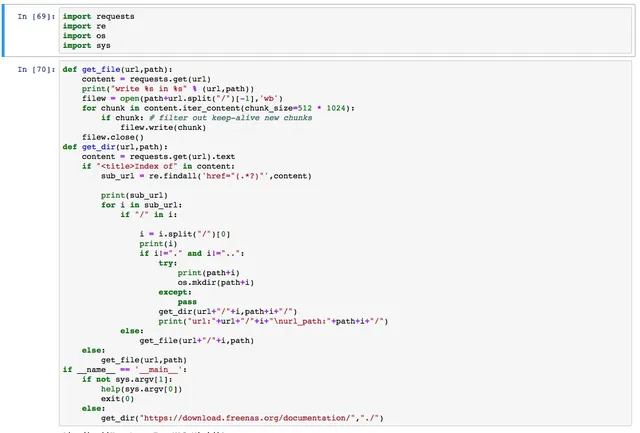
After implementing python for Qianqian Music mp3 download, some users found that many songs couldn’t be searched on Qianqian Music. So today, Chunjian Muke extended the download functionality to Kugou Music, with source code provided.
Using the same approach, first search for a song directly on the Kugou official website. Then, open the network monitor in Google Chrome and search for the same keyword again. You’ll then be able to find the API information (Note: It’s best to view the network requests during the second search to filter out unnecessary information).
1. Analyzing Search API Information
For detailed request information, after reading the article on Qianqian Music, I believe everyone is familiar with it. callback is prefixed with a 13-digit timestamp, and _ is a 13-digit timestamp.
2. Analyzing Playback API Information
Now that we understand the detailed search request and its results, let’s look at the music download address. Click on the first song to play it.
The URL is https://www.kugou.com/song/#hash=0D0CD85787B2988DC372A315EFD632FC&album_id=2713184. From this, we know that to get the music download address, we only need a hash and an album_id. Let’s go back to the search results and look at these two pieces of information in the response.
You just need to parse the JSON result and retrieve the information. json_page_source["data"]["list"][0]["AlbumID"] and json_page_source["data"]["list"][0]["FileHash"] will provide the necessary information for downloading.
Directly check the network, refresh, and then inspect the network connections to find the actual request that fetches the MP3 address from the myriad of requests.
It’s also JSON, same approach. play_url is the MP3 address, and lyc (lyrics) are returned directly in text format. json_page_source["data"]["play_url"] gets the MP3 address, and json_page_source["data"]["lyrics"] gets the LRC lyrics.
3. Python Implementation for Search and Download
Now that the API analysis is clear, we can directly implement it in Python. Kugou has stricter restrictions on crawlers, and for some reason, requests couldn’t get the information. Therefore, I had to use the versatile selenium to call the browser and get the source code, then use requests to download the MP3. Here’s the code:
#!env python
# -*- coding: utf-8 -*-
import requests
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re,json,time,sys,os
CHROME_PATH = os.getcwd()+"/chromedrive"
#print(CHROME_PATH)
def helpmessage():
msg = r'''
/ / / /
//// //// //// ////
/////////////////////////
//////////////////////////
/// ///
/ This program is brought to you by Chunjian Muke /
/ Published on [www.bobobk.com](https://www.bobobk.com) /
// The program will open a website after launching //
// Please don't rush to close it //
/ Author: Chunjian Muke /
/ Kugou Music Downloader /
// Usage instructions are displayed when the program runs //
// If you have any questions, please leave a message on //
/ the blog page or send an email to /
/ 2180614215@qq.com /
// Downloaded music is for learning and exchange only //
// Strictly prohibited for commercial use //
/ Please delete within 24 hours /
/ /
/// ///
//////////////////////////
/////////////////////////
//// //// //// ////
/ / / /
'''
print(msg)
#####The pattern is generated by boxes. If you don't understand, please refer to [https://www.bobobk.com/185.html](https://www.bobobk.com/185.html)
def get_kugou_mp3_address_and_download(song_hash,albumid):
apiurl= "[https://wwwapi.kugou.com/yy/index.php](https://wwwapi.kugou.com/yy/index.php)"
chrome_url = apiurl+"?"+"r=play/getdata&hash=%s&album_id=%s" % (song_hash,albumid)
browser = webdriver.Chrome(CHROME_PATH)
browser.get(chrome_url)
text = json.loads(browser.page_source.split("")[1].split("")[0])
browser.close()
song_address = text["data"]["play_url"]
songname = text["data"]["author_name"]+"_"+text["data"]["album_name"]+"_"+text["data"]["song_name"]
mp3w = open(songname+".mp3",'wb')
mp3r = requests.get(song_address)
for chunk1 in mp3r.iter_content(chunk_size=512 * 1024):
if chunk1:
mp3w.write(chunk1)
mp3w.close()
lrc = open(songname + ".lrc",'w')
lrc.write(text["data"]["lyrics"])
lrc.close()
def search_music(keyword):
if keyword in ["exit",u"退出"]:
print(u"You chose to exit the current program")
sys.exit(0)
callback = "jQuery112404564878798811507_"+str(round(time.time()*1000))
hua = str(round(time.time()*1000))
basic_url = '[https://songsearch.kugou.com/song_search_v2](https://songsearch.kugou.com/song_search_v2)?'
kugou_s_url = basic_url + "callback=%s&keyword=%s&page=1&pagesize=40&userid=-1&clientver=2.7.8&platform=WebFilter&tag=em&filter=2&iscorrection=7&privilege_filter=0&_=%s" % (callback,keyword,hua)
browser = webdriver.Chrome(CHROME_PATH)
browser.get(kugou_s_url)
songlist = json.loads(browser.page_source.split(callback)[1].split("...")[0][1:-2].strip())["data"]["lists"]##...replaced due to web page display issue
browser.close()
return songlist
def main():
while True:
song = input(u"Please enter the name of the music, artist, or album you want to download: ").strip()
if song!="":
break
songlist = search_music(song)
page = 1
print("nSearch results are as follows")
for i in range(len(songlist)):
print("%d:%s_%s_%s" % (i+1,songlist[i]["SingerName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip(),songlist[i]["AlbumName"],songlist[i]["SongName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip()))
print("n")
while True:
songid = input(u'Please select the number in front of the song(s) you want to download.nFor multiple songs, separate with spaces, e.g., "1 2" then press Enter.nInput non-numeric characters to exit selection and enter search mode.nTo download all, please enter 100000:').strip()
if songid == '':
continue
try:
songid = [int(i) for i in songid.strip().split()]
# print(songid)
if songid[0] != 100000:
for song in songid:
# print(songlist[song-1]["FileHash"])
# print(songlist[song-1]["AlbumID"])
songname = songlist[song-1]["SingerName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip()+"_"+songlist[song-1]["AlbumName"]+"_"+songlist[song-1]["SongName"].replace("<","").replace(";",'').replace(">","").replace("em",'').replace("/",'').strip()
try:
get_kugou_mp3_address_and_download(songlist[song-1]["FileHash"],songlist[song-1]["AlbumID"])
print(u"n-------Congratulations, current song--%s--downloaded successfully---------n" % songname)
except:
print("Network error")
print(u"To exit, please type 'exit' or '退出'")
else:
print("Starting to download all searched songs, please wait patientlynn")
for songid in songlist:
print("-------Downloading song--------%s----------" % songid[1])
time.sleep(2)
try:
get_mp3_address_and_download(songid[0])
print("-------Congratulations, song--------%s---downloaded successfully-------n" % songid[1])
except:
print("Error occurred while downloading %s" % songid[1])
except:
print("Incorrect number, re-searching songs.n")
break
main()
if __name__=='__main__':
print("nnn")
# search_music(u"可不可以")
# get_kugou_mp3_address_and_download("96E064A41AB84EBE4C03C6AAE3CB9334","9618875")
helpmessage()
os.system("start [https://www.bobobk.com/234.html](https://www.bobobk.com/234.html)")
print("nnn")
while True:
# main()
try:
main()
except:
print(u"Closing program in 2 seconds")
time.sleep(2)
sys.exit(0)
Summary
This article is a follow-up to python for Qianqian Music mp3 download, as many resources were found to be missing. Therefore, I added this Kugou Music download program. During the process, I encountered obstacles when trying to obtain web pages using requests, so I had to resort to using selenium to call the browser. However, the outcome is positive, and the Kugou Music download was successfully implemented.